
We are in the midst of an AI revolution
While there is plenty of AI hype permeating the tech world right now, there is also significant, real progress being made and there are real business cases and experiences being unlocked.
Rapid advancements and a hyper-convergence of technologies are unlocking unprecedented opportunities at the edge — the edge being intelligent products that exist in the physical world and interface with us and our environment from our wearables to our laptops to our cars — for those with the ambition to win.
- AI models, including GenAI, have made huge leaps in the past year. Massive Multitask Language Understanding (MMLU) benchmark scores as a benchmark of AI performance have increased threefold. And models are more accessible than ever. No-code platforms are enabling those without a PhD in computer science to develop prototypes. Significant progress has been made in creating smaller, more efficient models allowing for generative functionality to be deployed at the edge.
- AI chips that run models on edge devices have progressed significantly as well. NVIDIA is leading the GPU market and has also developed a number of platforms for edge applications like Jetson and IGX Orin. Silicon companies across the spectrum of processing and power optimization are delivering new AI-focused silicon offerings as well.
- Connectivity has continued to progress. From ubiquitous Bluetooth Low Energy and WiFi to 5- and 6G, to low-earth orbit satellite services like Starlink and Kuiper, linkage to the cloud has never been this pervasive.
- Hardware and embedded systems have also continued to progress. Battery technologies and miniaturization and power optimization of embedded systems as well as sensing and interface technologies have all been developing, enabling new form factors and use cases.
With all of these enabling technologies progressing, edge devices are more capable than ever and we are able to make use of the data harvested from edge devices better than ever before. Connected devices will drive $12.6 trillion of economic value by 2030 with 1 yottabyte (1024 bytes) of data being generated annually. At the moment, less than 25% of sensor data is processed due to high cloud transmission and compute costs. (Source: McKinsey, Nature)
Gartner predicts that, by 2025, more than 55% of all data analysis by deep neural networks will occur at the point of capture in an edge system — up from less than 10% in 2021. Bringing the compute closer to the point of capture, Edge AI delivers time-sensitive insights, access to large volumes of dynamic, first-party data, and the ability to change the physical world. It significantly reduces the cost of processing and transmitting data by leveraging local processors and memory and limiting the data sent to the cloud down to only what’s needed. This can also have a big positive impact on privacy and security by pre-processing data before it is saved and by keeping some data from ever reaching the cloud.
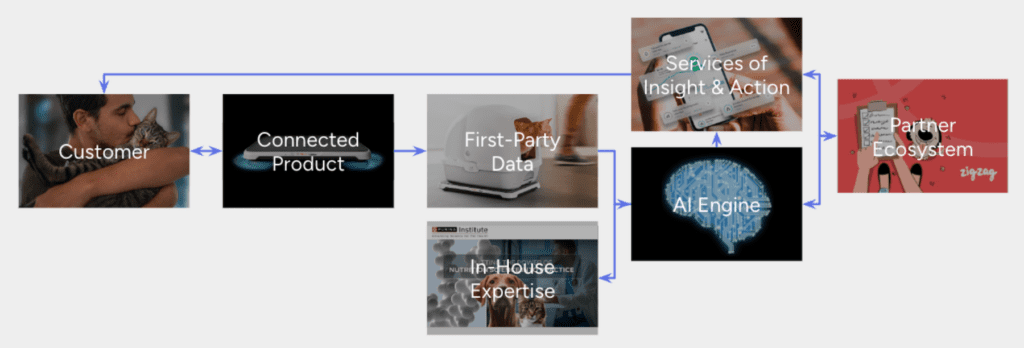
Leaders can establish a value exchange flywheel, delivering services and insights in exchange for novel first-party data that builds momentum, increasing loyalty and competitive advantage.
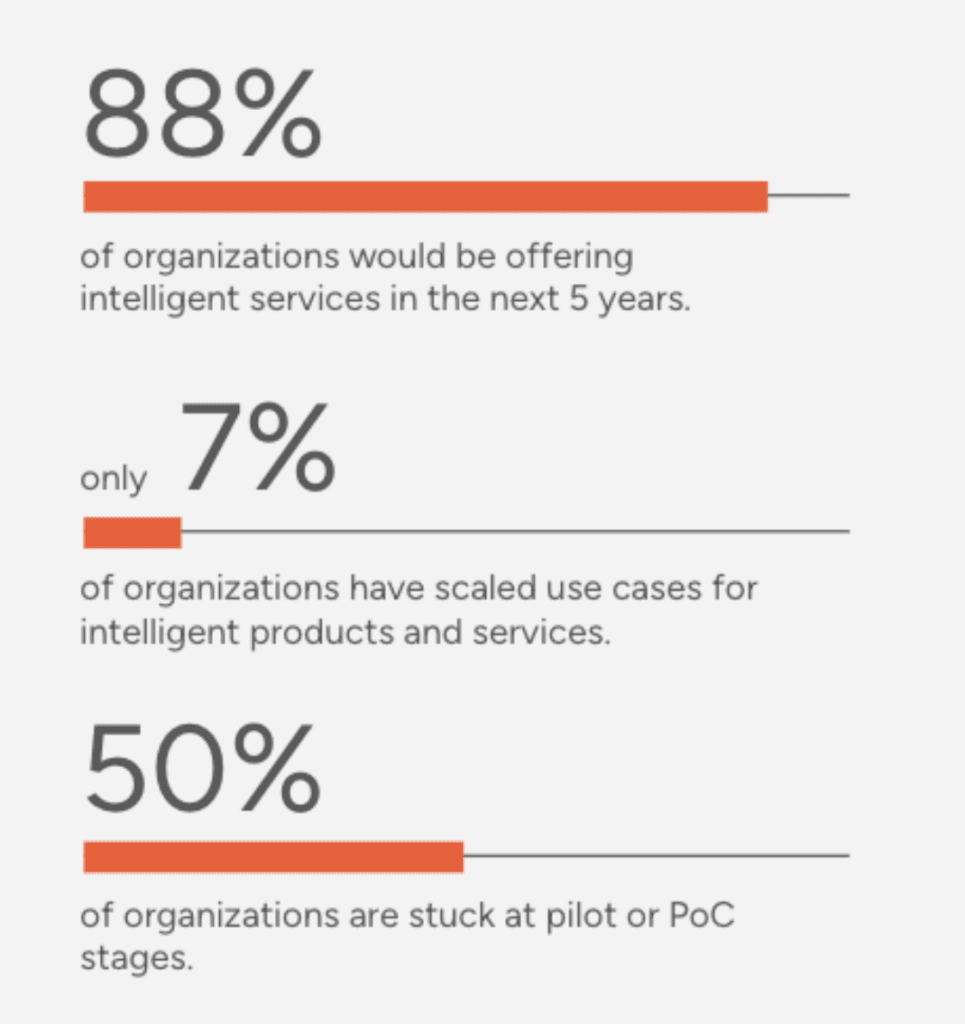
But many companies are stuck at the POC and prototype stages, struggling to launch and monetize AI-based products & services
More and more companies are seeing the potential for intelligent products and services to unlock operational efficiency and deliver differentiated customer experiences. And the latest tools and platforms have made it easier to develop proofs of concept. But what we see is that there is a big leap between POCs and successful products in the market and many companies fall into traps at this stage of the game.
We’ve seen 4 consistent challenges companies face when realizing AI-enabled products at scale and have recommendations for mitigating them based on real-world projects
Lack of quality training data
The challenge:
When pursuing new areas of business value and user experience differentiation that justify new product development, suitable training data often doesn’t yet exist and must often be collected and labeled to enable model development. This effort can take more time and effort than the AI model development itself.
An example:
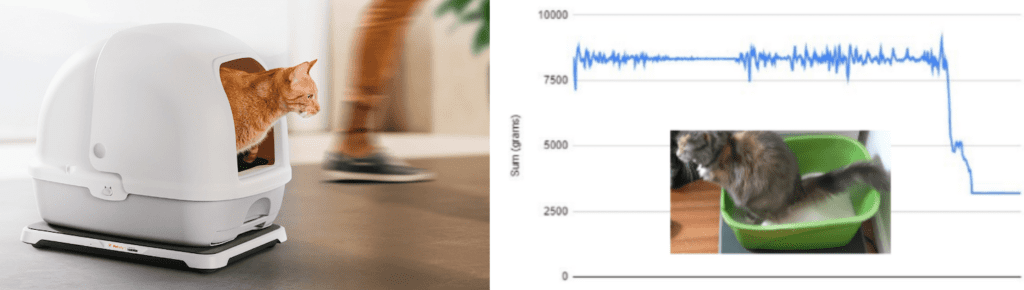
When working with Nestle Purina on Petivity, to avoid invading user privacy, the end-product sensor could not include a camera. Only load cell data could be used to measure pet bathroom events. We created a data collection engine linking triggered time-synced video with sensor event data to enable tagging and leverage of >300,000 data points. This enabled sophisticated model development and much easier iteration as the sensor evolved
Our recommendation:
If relevant training data doesn’t exist, your sensor data doesn’t capture ground truth on its own, and significant data is needed for model development, build a data collection and tagging engine, which might be different from the end product. While this can be a major investment, it will enable much more rapid development and ongoing iteration.
Consider leveraging synthetic data for the training where possible as well. This enables much faster training with control over the training data. The risk though is that transference to real-world use cases might be too narrow with synthetic data alone.
Concurrent HW & AI Development
The challenge:
When a new product acts as the sensor for its own edge AI, a Catch-22 arises: what are the specs for the sensor? What’s good enough for the AI? How can we develop both at the same time, each without the other?
An example:

For a real-time crowd-scale face identification device, we leveraged existing video of crowds before our custom device was ready and generating its own data. We were able to start training our model on this stock video data and experiment with the resolution and frame rate of the video which could still hit our accuracy and latency specs, helping to inform the specs for our sensor and AI.
Our recommendation:
Push the boundaries on only one axis if possible. Stay within a proven zone (a high TRL) for either the sensor or the AI or be willing to commit to iterative development. Start as off-the-shelf as possible for the sensor with a high data quality headroom in a non-form factor development setup. Manipulate this data to define the lowest input fidelity that still delivers the accuracy needed.
Requirements force custom HW
The challenge:
For many applications in resource-constrained devices, leveraging off-the-shelf modules may not be feasible for production products—custom, embedded systems can be required to achieve form factor, battery life, latency, and cost requirements. Each custom hardware spin results in a significant cost and schedule impact.
An example:

When working with Google and Levi’s on Jacquard, we were creating a first-of-its-kind product that synthesized touch-sensitive fabric signals to enable gesture input just like on a touchscreen, but on a jacket sleeve. To blend into the jacket, the electronics needed to fit on the cuff, requiring a small microprocessor and battery. We leveraged a low-power AI classifier for gesture inference and developed a custom embedded system to gather sensor data, analyze it, and send commands via BLE. We did this initially on a non-form-factor (NFF) board that made it easier to develop and probe our model before the final product embodiment was available.
Our recommendation:
Define critical requirements for the system such as form factor, battery life, cost and latency up front based on market and user research. These cast a long shadow on both the AI and the hardware architecture and should tell you up front if a custom path is needed. Plan in some headroom for memory and processing to handle inevitable feature creep and new model iterations. Expertise in both AI model minimization as well as embedded systems are required to co-design custom embedded systems with edge AI.
Production environment nuances
The challenge:
There is a good reason that the NASA Technology Readiness Level scale differentiates between a lab, relevant, and production environment. Nuances and edge cases in a production environment can skyrocket, causing major issues for edge AI-enabled products that didn’t materialize during development.
An example:

A real-time edge vision system we developed was based on an array of specifications that were all reasonable in isolation and tested in our labs. It was only through real-world testing that we learned that the lighting in the production environment did not align with the specs, necessitating significant changes to the application and model.
Our recommendation:
Capture data from real-world vs. controlled environments and leverage tools and approaches like non-form factor development hardware, FMEA, modeling and simulation, and accelerated testing to help minimize surprises. That said, there is no substitute for real-world testing. Bake real world pilots into the development plan.
Conclusion
Edge AI-enabled products represent a significant evolutionary step for the Internet of Things. The value which can be unlocked through use cases from industrial predictive maintenance to manufacturing defect detection to biometric-based health insights to next-generation digital assistants is very significant. And by operating at the edge in the physical environment, unique first-party data can be gathered and leveraged — enabling owners of this data and these AI-based services to grow a significant competitive advantage with a positive feedback loop flywheel.
There are clear realities and challenges companies must overcome to successfully launch AI-enabled products and services at scale but there are ways to navigate these with the right experience and expertise on your side.
This post is a summary of the presentation Jeff delivered at the Edge Impulse Imagine conference at the Computer History Museum in Mountain View, CA on September 23.
